红外小目标
红外小目标
数据集
| 数据集名称 | 链接 | 对应代码 |
|---|---|---|
| IRSTD-1k | https://drive.google.com/file/d/1JoGDGF96v4CncKZprDnoIor0k1opaLZa/view | 有 |
| 地/空背景红外弱小飞机目标检测跟踪数据集 | http://www.csdata.org/p/387/ | |
| 复杂背景下红外弱小运动目标检测数据集 | https://www.scidb.cn/en/detail?dataSetId=808025946870251520 | |
| FLIR红外数据集 | https://pan.baidu.com/s/11GJe4MdM_NH6fuENCQ2MtQ 提取码:019b | |
| OTCBVS红外行人数据集 | https://github.com/SoonminHwang/rgbt-ped-detection | |
| NUAA-SIRST | https://github.com/YimianDai/open-sirst-v2 | |
| NUDTSIRST | https://pan.baidu.com/share/init?surl=WdA_yOHDnIiyj4C9SbW_Kg&pwd=nudt | 有 |
| 红外飞机小目标数据集 | https://www.scidb.cn/en/detail?dataSetId=720626420933459968#p2 | |
| 红外无人机目标视频数据集 (UAV Dataset, UAVD) | https://sites.google.com/view/grli-uavdt/%E9%A6%96%E9%A1%B5 | 这个是可见光 |
| SIRST-5k | https://github.com/luy0222/SIRST-5K | 使用负片生成策略合成的数据集 |
| https://pan.baidu.com/share/init?surl=EG-loK86aWJL7M6bPQjivA&pwd=1234 |
硕博士学位论文快速阅读(近5年)红外遥感小目标检测
复杂背景下红外运动小目标检测方法研究 任向阳
基于深度学习的红外弱小目标检测方法的研究 冯鹏

经典的基于单帧的红外弱小目标检测方法
形态学滤波
加权局部对比度算法
低秩稀疏分解(红外图像的每个像素构成可由三部分构成,即背景、目标和噪声)
对比方法参数设置
红外弱小目标的检测与跟踪方法研究
第一类是目标聚焦法,它根据目标特征,将小目标与红外背景进行区分.
第二类是基于背景抑制的方法,主要关注背景的预测或保留,通过计算输入图像和预测背景之间的残差来实现目标的检测,其中顶帽变换11-13在红外弱小目标检测中应用广泛。
第三类是基于学习的方法。
定义:光电仪器工程师协会(SPLE)将小目标定义为总空间范围小于80个像素点(99),在256256个像素点的图像中所占比例小于0.12%的目标[41]。在某些论文中,红外弱小目标也被称为暗目标[42],小目标[43],低可观察目标,红外点目标[44]等。、
经典检测算法
顶帽变换
基于局部灰度概率分布的小目标检测算法
基于奇异值分解的红外弱小目标检测
基于背景自适应多特征融合的弱小目标检测
基于空频域映射和虚警抑制的弱小目标检测算法
基于深度学习的红外弱小目标检测算法研究
传统图像处理的检测方法和基于深度学习的检测方法,
基于传统图像处理的检测方法通过图像去噪,平滑,特征匹配等方法进行目标检测
基于深度学习的红外弱小目标检测与主动跟踪研究
根据国际光学工程学会(SPIE)的定义,红外弱小目标为尺寸不大于9*9像素的目标。其中,“弱”体现在目标的局部信杂比低,与周围背景差异小,难以分割。“小”体现在目标所占全部像素的比例少,一般不超过总像素数的0.12%,由于像素数少,一般没有纹理特征,呈点状。
传统方法
传统红外弱小目标检测算法主要有区域形态学滤波法、小波变换法、视觉注意力模型方法、假设检验法等。基于背景抑制加阈值处理的检测方法根据红外图像中真实目标占用像素非常少的特点,将真实的目标点认为是整幅图像中的高频信息,而背景的灰度变化比较平缓,可以认为是整幅图像中的低频信息。利用这种差别,基于背景抑制的红外弱小目标检测算法将红外图像中的低频部分灰度抑制为0,保留高频的噪声像素和真实目标的像素,再采用阈值分割方法过滤出目标。当然直接进行滤波再进行阈值分割的方法一般精确率较低或者检出率较低,无法直接应用于红外弱小目标检测跟踪系统,针对这些问题,各种改进的算法被提出来。
Weiping,Yang ====》Li,J====》Bai,Kun===》Cheng,Wenxiong===》
基于神经网络的红外弱小目标检测算法
双阶段
单阶段
Detection of infrared small targets using featurefusion convolutional network文献[42] 基于DenseNet和YOLO检测框架提出了红外目标的检测算法,该算法的精确率和检出率都非常高,但是目标的局部信杂比则非常高,且在文献中展示出的部分目标具有比较明显的轮廓,因此该算法可能不适合红外弱小目标的检测。
文献[43]提出了用于一种增强红外图像的CNN网络,利用MNIST数据集中的手写图像来模拟长程红外图像的目标弱、背景杂波、对比度低等特性,对微弱的红外图像进行了增强。
文献[44]提出一种基于深度学习的弱小目标检测方法,利用全卷积递归网络学习复杂背景下弱小目标的特征,该方法基于语义分割任务,能够将每个像素归类为背景和目标类别,网络中使用了残差模块。虽然模型参数较少但是逐像素的分类势必会为后续处理带来相当大量的计算。
文献[45]提出了一种多帧检测的深度学习检测算法,但是其红外目标数据是虚拟构建的,无法说明其在真实红外检测跟踪设备上检测的有效性。
最近也有研究者提出了基于循环神经网络RNN和LSTM的检测算法[46],在同一管道内使用三维卷积网络(3D ConvNet)和长短期记忆网络(LSTM)来实现红外小目标的检测和预测。
文献[48]提出了一种基于注意力机制卷积长短时记忆神经网络的弱小目标轨迹检测算法,通过3D卷积核提取连续15帧红外图像序列的短期时间维信息和空间维信息,结合卷积长短时记忆网络提取红外序列的长期时空信息,利用注意力机制关注弱小目标运动轨迹有关的关键信息并舍弃无关信息,实现了网络端对端的预测输出
基于深度学习的红外弱小目标检测研究
根据国际光学工程协会(Society of Photo-Optical Instrumentation Engineer, SPIE)对小目标的定义,它是指所占像素数量不超过9*9的区域,对于一副尺寸为256256的图像而言,目标像素数仅占整副图像的比例约0.15%[3]。
基于深度学习的机载红外弱小目标检测技术研究
红外探测方式具有抗干扰能力强、隐蔽性好、灵敏度高、全天候工作等优点[2]
红外弱小目标检测的 深度学习方法研究
深度学习的部分就是讲的目标检测的发展历程
基于YOLOv5的复杂背景下红外弱小目标检测方法研究
单帧===》基于滤波、基于人类视觉系统、基于图像数据结构和基于深度学习四类算法
多帧===》基于传统和基于深度学习
基于深度学习的红外弱小目标检测与跟踪方法研究
基于深度学习的红外图像序列中弱小目标检测跟踪算法研究
基于滤波的背景抑制类算法
基于滤波的背景抑制类算法
基于低秩稀疏优化的算法
基于深度学习的红外弱小目标检测算法
(1)纯网络端到端模型
(2)手工特征深度网络联合模型
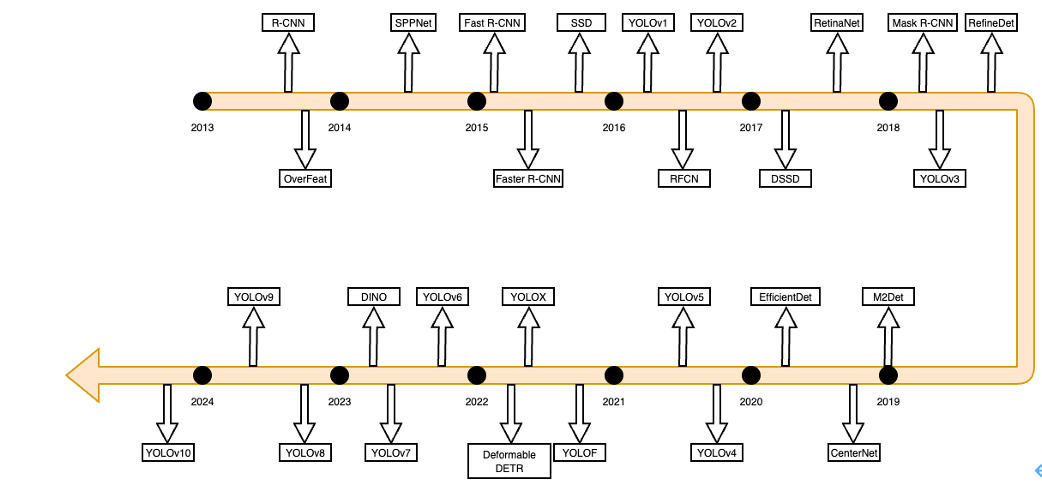
梳理脉络(博客、综述、学位论文,优缺点),时间轴,表格形式

基于传统方法的红外小目标检测算法与基 于深度学习的红外小目标检测算法
红外小目标缺少相对明显的颜色、形状、 纹理等信息,且边界模糊,这使得对其的检测更具挑 战。 更困难的是,建筑物、流动的云等干扰物的存在 使得红外小目标容易被干扰和淹没[4] 。 再者,由于 高于绝对零度的物体都可以产生红外辐射,检测算 法的虚警率会大幅度提升。
优缺点
红外成像技术凭借穿透能力强,工作距 离远,受天 气 影 响 较 小, 抗 外 界 干 扰 能 力 强、 且 测 量精度高、能持续工作等优点,使得基于红外成像 技术得到的图像进行的目标检测方法得到了众多 领域 的 广 泛 应 用, 如 辅 助 医 学 诊 断[1] 、 缺 陷 检 测 [2] 、海上船舰搜寻[3] 等。
引用文章梳理
传统单帧
袁帅,延翔,张 昱 赓, 等. 双 邻 域 差 值 放 大 的 高 动 态 红 外弱小目标检测 方 法 ( 特 邀 ) [ J ] . 红 外 与 激 光 工 程,
2022,51(4) :20220171.
吴文怡. 红外图像序列中弱小目标检测与跟踪技术研
究[ D] . 南京: 南京航空航天大学,2008
潘胜达,张素,赵明,等. 基于双层局部对比度的红外弱小
目标检测方法[J]. 光子学报,2020,49(1):0110003
传统多帧
娄康,朱志宇,葛慧林. 基于目标运动特征的红外目标 检测与 跟 踪 方 法 [ J ] . 南 京 理 工 大 学 学 报, 2019, 43
(4) :455 - 461.
Bae T W. Small target detection using bilateral filter and
temporal cross product in infrared images [ J ] . Infrared
Physics & Technology,2011,54(5) :403 - 411.
Liu D, Zhang J, Dong W. Temporal profile based small
moving target detection algorithm in infrared image se⁃
quences[ J ] . International Journal of Infrared and Milli⁃
meter Waves,2007,28(5) :373 - 381.
深度学习-检测算法
安防
段应奎. 基于深度学习的人脸识别技术在安防领域的
应用[ J] . 中国安防,2017,(11) :72 - 74.
自动驾驶
张新钰,高洪波, 赵 建 辉, 等. 基 于 深 度 学 习 的 自 动 驾 驶技术综述[ J] . 清华大学学报:自然科学版,2018,58 (4) :438 - 444.
智能医疗
施俊,汪琳琳,王 珊 珊, 等. 深 度 学 习 在 医 学 影 像 中 的 应用综述[ J] . 中国图象图形学报,2020,25 ( 10 ) :1953 - 1981.
智慧家居
包晓安,徐海,张 娜, 等. 基 于 深 度 学 习 的 语 音 识 别 模 型及其在智能家居中的应用[ J] . 浙江理工大学学报: 自然科学版,2019,41(2) :217 - 223.
单阶段
yolo
Redmon J, Divvala S, Girshick R, et al. You only look once:unified,real⁃time object detection[ C] / / Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:779 - 788.
SSD
Liu W,Anguelov D,Erhan D,et al. Ssd:single shot multi⁃ box detector[ C] / / European Conference on Computer Vi⁃ sion. Springer,Cham,2016:21 - 37.
Anchor⁃Free
Law H, Deng J. Cornernet: detecting objects as paired keypoints [ C] / / Proceedings of the European Conference on Computer Vision( ECCV) ,2018:734 - 750.
双阶段
R-CNN
Girshick R,Donahue J,Darrell T,et al. Rich feature hier⁃
archies for accurate object detection and semantic segmen⁃
tation[ C] / / Proceedings of the IEEE Conference on Com⁃
puter Vision and Pattern Recognition,2014:580 - 587.
MaskR⁃CNN
Girshick R. Fast R⁃cnn[C] / / Proceedings of the IEEE Inter⁃
national Conference on Computer Vision,2015:1440 - 1448.
Faster⁃RCNN
Ren S,He K,Girshick R,et al. Faster R⁃CNN:towards re⁃
al⁃time object detection with region proposal networks
[ J] . IEEE Transaction on Pattern Analysis & Machine In⁃
telligence,2017,39(6) :1137 - 1149.
数据集
SIRST 数据集
Dai Y,Wu Y,Zhou F,et al. Asymmetric contextual modu⁃ lation for infrared small target detection[ C] / / Proceedings of the IEEE / CVF Winter Conference on Applications of Computer Vision,2021:950 - 959
NUDT⁃SIRST 数据集
Li B,Xiao C, Wang L, et al. Dense nested attention net⁃ work for infrared small target detection[ J] . Journal of La⁃ tex Class Files,2015,14(8)
红外飞机小目标数据集
汪嘉鑫,徐贵川, 于 婷 洋, 等. 复 杂 红 外 背 景 中 运 动 小 目标快速跟踪技术[ J] . 应用光学,2021,42(3) :443.
地 / 空背景下红外图像弱小飞机目标检测跟 踪数据集
回丙伟,宋志勇,范红旗,等. 地 / 空背景下红 外 图 像 弱 小飞机目 标 检 测 跟 踪 数 据 集 [ J ] . 中 国 科 学 数 据, 2020,5(3) :286 - 297.
最新的红外遥感小目标检测模型,最新有哪些模型(榜单去看,有源码模型)
| 名称 | 地址 | 数据集 | |
|---|---|---|---|
| SIRST-5K | https://github.com/luy0222/SIRST-5K | 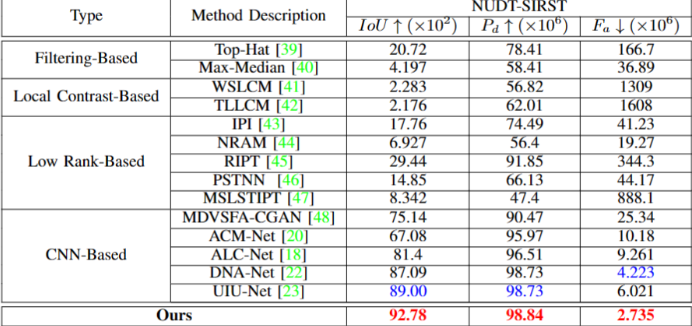 |
|
| SCTransNet | https://github.com/xdFai/SCTransNet |   |
NUDT_SIRST94.09 |
| MiM-ISTD | https://github.com/txchen-ustc/mim-istd |  |
NUAA-SIRST 80.92 |
| MSHNet | https://github.com/ying-fu/MSHNet |  |
|
| IRSAM | https://github.com/IPIC-Lab/IRSAM |  |
IRSTD-1K 73.69 |
| MRF3Net | https://github.com/Temperature-ai/MRF3Net |  |
|
| 模型名称 | 简介 | 代码地址 |
|---|---|---|
| ALCNet(2020) | 提出了一种用于红外小目标检测的新型模型驱动深度网络,该网络结合了判别网络和传统模型驱动方法,以利用标记网络和传统模型驱动方法 | https://github.com/YimianDai/open-alcnet |
| ACM(2021) | 提出了一种专门针对红外小目标检测设计的不对称上下文调制模块。除了利用自顶向下的全局上下文反馈外,还加入了基于逐点通道注意力机制的自底向上的调节路径,以更好地突出小目标。 | https://github.com/YimianDai/open-acm |
| DNA-Net(2022) | DNA-Net通过引入DNIM(实现高层和低层特征之间的渐进式交互)和CSAM(基于DNIM之上,进一步增强多级特征,从而更好地融合并利用小目标的上下文信息。)解决了小目标丢失的问题。 | https://github.com/ YeRen123455/Infrared-Small-Target-Detection. |
| ISNet(2022) | 利用泰勒有限差分法对目标进行复杂的边缘特征提取,以增强目标和背景的灰度差异。 | https://github.com/RuiZhang97/ISNet |
| IAANet(2022) | 提出的IAANet方法通过使用区域提议网络(RPN)获得粗略的目标区域,然后利用Transformer编码器建模这些区域内像素间的注意力关系,最后通过分类头输出最终的检测结果。 | https://github.com/kwwcv/iaanet |
| UIU-Net(2023) | 提出了一种简单有效的“U-Net in U-Net”框架,简称UIU-Net,用于检测红外图像中的小物体。顾名思义,UIU-Net 将一个微小的 UNet 嵌入到一个更大的 U-Net 主干中,从而实现对象的多层次和多尺度表示学习。 | https://github.com/danfenghong/IEEE_TIP_UIU-Net |
| ABC(2023) | 提出了一种称为双线性相关注意力(ABC)的新模型,该模型基于 Transformer 架构,并包括一个卷积线性融合变压器(CLFT)模块,该模块具有用于特征提取和融合的新颖注意力机制,可以有效地增强目标特征并抑制噪声。此外,我们的模型还包括位于网络较深层的 U 形卷积扩张卷积(UCDC)模块,它利用较深层特征的较小分辨率来获取更精细的语义信息。 | https://github.com/PANPEIWEN/ABC |
| MTU-Net(2023) | 设计了一个视觉变换器(ViT)卷积神经网络(CNN)混合编码器来提取多级特征。局部特征图首先由几个卷积层提取,然后输入多级特征提取模块(MVTM)以捕获长距离依赖性。 | https://github.com/TianhaoWu16/Multi-level-TransUNet-for-Space-based-Infrared-Tiny-ship-Detection |
| MSHNet(2024) | 提出了一种新的损失函数,用于提高红外小目标检测(IRSTD)的性能。设计了一个简单的多尺度头部加入到标准的U-Net架构中,通过对每个预测尺度应用SLS损失,MSHNet在红外小目标检测上实现了显著的性能提升 | https://github.com/ying-fu/MSHNet |
| MIM-ISTD(2024) | 定制了 Mamba-in-Mamba (MiM-ISTD) 结构以实现高效的 ISTD | https://github.com/txchen-USTC/MiM-ISTD |
| IRSAM(2024) | 提出了 IRSTD 的 IRSAM 模型,它改进了 SAM 的编码器-解码器架构,以学习更好的红外小物体的特征表示 | https://github.com/IPIC-Lab/IRSAM |
| SCTransNet(2024) | 该模型通过使用空间通道交叉变换器块(SCTB)来增强不同级别的编码器之间的交互,并利用长距离跳过连接来改善信息流动。 | https://github.com/xdFai/SCTransNet |
关注红外小目标检测里存在问题(小目标、密集、红外),决定后期哪些模块和优化是可以考虑的(注意力等等)
(1)目标在成像时距离红外探测器往往很远,导致红外图像上目标通常表现为十几个像素,甚至只占有一个像素。目标的形状、纹理等结构特征信息丢失,增加了目标检测的难度。 (2)远距离成像时,红外图像场景跨度大,背景复杂。目标的红外辐射受到大气衰减、传感器自身噪声等因素的影响,图像中的目标信噪比往往很低,导致目标常常淹没在背景中。 (3)在某些应用场景下,特别是军事用途中,要求检测算法具有实时性。这又增加了红外弱小目标检测任务的难度
1、噪声复杂性
2、弱纹理表达性
3、尺度分布差异性
1、目前公开的红外弱小目标数据集太少,仅有1个公开的红外数据集地/空背景下红外图像弱小飞机目标检测跟踪数据集,这个数据集有地面背景和天空背景的红外小目标数据,其中地面背景的数据背景比较复杂,检测比较有挑战性。但是其中大部分目标距离不够远,具有明显的轮廓。除此之外,相比于COCO数据集和ImageNet数据集来说,数据量仍然不够大,种类不够丰富。
2、目前红外弱小目标检测的研究文献很少提到局部信杂比,在远距离检测上,局部信杂比是一个非常重要的指标,能够衡量算法检测到目标的强弱程度,能够稳定检测到低局部信杂比的目标的算法在远距离检测上的意义重大,能够提高预警系统的灵敏程度,为防御系统或者攻击系统提供更充足的准备时间。
3、目前的研究文献,无论是基于传统图像处理方法还是基于神经网络的算法,仍然以单帧检测算法为主,单帧的算法没有利用到时间维度上小目标位置的连续性,在极低局部信杂比下,其精确率与检出率必然难以同时提高,其检测的稳定性不会高于多帧检测算法。在计算机NPU、FPGA等硬件算力越来越强大的背景下,更应该集中于多帧算法,在保证实时性的情况下,不断提高红外弱小目标检测的精确率、召回率,提高检测的距离。
4、红外检测与跟踪系统的工作方式一般为主动跟踪,也就是说,在检测到小目标后必须控制跟踪系统对目标进行连续跟踪,其背景在不断变化,帧差法等算法将无法适应这样的工作环境。所以必须考虑到系统主动跟踪的工作特性。
1)目标特征少
基于深度学习的目标检测算法通过大量样本和标签对模型参数进行训练,提取目标潜在特征,但小目标自身缺乏一定纹理信息,可用于判别特征过少,导致模型训练效果差,拟合能力较弱。
2)分辨率与语义信息之间的矛盾
小目标由于尺度较小、与背景灰度差别较弱,往往淹没在复杂的杂波背景中,需要较高的分辨率去“聚焦”目标,而深度学习是通过逐层卷积衰减尺度来学习更多语义表示,最后使用一个特征层提取语义特征进行检测,这是一个深层网络的内在矛盾,在图像中,大目标具有较深的语义信息,可以获得较好的测试结果,但小目标仅在一定邻域内与背景有强对比度,无明显高层语义特征,且由于灰度、尺度都较小,在多次池化、卷积中目标会被背景平滑掉,难以在高层的“视野”中具有较好的特征表现,提取到的特征对小目标不敏感,导致目标会被漏检。
3)目标尺度小造成定位难
机载小目标在整张图中所占像素比例较小,导致训练时正负样本严重不均衡,全图目标所占像素比例仅为0.08,而现有算法框架多是采用锚框回归方式进行目标定位,通过在图像中生成一系列锚框来回归目标位置,此时在正样本周围进行IOU回归判别时,预测框轻微偏斜,会导致交并比急速变化,在正负样本间多次震荡。检测模型会更倾向于大/中尺度目标的检测,忽略小目标,造成小目标检测结果无法提升[48]
1)目标小。当红外成像系统的成像距离较远时,红外图像中的弱小目标通常很小,像素占比少,目标分辨率低。
2)强度弱。红外弱小目标的辐射强度较弱、信噪比低,与周围环境的对比度低,通常不超过15%[2],目标显著性不强,常规的目标检测方法很难对复杂背景中的红外弱小目标进行准确率高、鲁棒性强的检测。
3)形状和纹理信息少。红外弱小目标通常以亮斑的形态存在,具有的形状和纹理信息十分有限,特征细节不明显,且在实际的应用场景中,目标所处的环境复杂多变,极易淹没在复杂的背景当中。
4)受噪声干扰。受成像器件灵敏度的限制,红外图像在生成和传输的过程中,易产生噪点、条纹噪声等干扰,使图像质量下降,给红外弱小目标的检测带来难度。
论文逻辑
背景和意义
第一版
红外成像是将目标的红外辐射和背景信息转换成红外图像的过程,其具有隐蔽性高,抗干扰性强,可远距离长时间工作等优点。在精确制导、防空预警等国防安全体系上,能够较早的检测到目标信息,为目标打击提供信息支撑,实现快速打击有着极高的军事及现实意义。随着科技发展,新型无人机、航拍器等空中设备逐渐增多,法律监管也在逐步完善,但是仍存在无人机的“黑飞”,间谍利用无人机对军事设施进行监视等问题。不仅要对空中安全做好监管,而且对于重点区域的安全保护和隐私防卫更需要注意。当前国际局势较为动荡,在俄乌冲突、巴以冲突中双方使用无人机探查敌情并进行战术打击,防空系统对于导弹等设备有着较高的防御能力,如美国的“爱国者导弹”系统,以色列的“铁穹”系统等,但是对于无人机这种低慢小无人机,其表现有待提高。由此可见无人机等这类小型目标的检测需要引起我们重视,提升我国的弱小目标的检测与跟踪能力对增强国家航空安全、军事实力非常重大的意义。
除此之外,随着计算机硬件的进步以及深度学习的快速发展,计算机视觉中各领域的精确度有了极大的提升,红外目标检测也有了较大的进步,并有许多研究者前赴后继的在这个方向上不懈努力着。红外弱小目标检测是指在红外图像中识别和检测那些亮度较低、对比度不高的小型目标的过程。根据国际光学工程学会(SPIE)的定义,红外弱小目标是指那些尺寸不超过9x9像素的目标。其“弱”主要体现在目标的局部信噪比很低,与周围背景的差异很小,难以被分离出来。而“小”则指的是目标所占的像素比例非常小,一般不超过总像素数的0.12%。由于像素数量少,这类目标通常没有明显的纹理特征,呈现为点状。此外红外成像系统依靠的是温差成像,相比于可见光图像,红外图像存在成像不清、容易被淹没在背景噪声中等问题,所以对该类图像的中的目标检测有着较大的挑战。红外弱小目标检测的难点具体可分为以下几个方面:
- 目标尺寸小:在远距离红外成像中,目标通常只占据图像中极少的像素数,甚至可能只有一个像素,这导致目标的形状、纹理等结构特征信息丢失,增加了检测难度。
- 信噪比低:红外图像中的目标信号容易受到大气衰减和传感器噪声等因素的影响,使得目标与背景之间的对比度较低,进而降低目标的可检测性。
- 复杂背景:远距离成像时背景复杂,加上目标本身的辐射强度弱,这些因素共同作用下,目标很容易被背景淹没。
- 实时性要求:特别是在军事应用中,需要快速响应,这进一步提高了对检测算法的要求。
- 数据集限制:目前公开的红外弱小目标数据集数量较少,且数据量相比其他领域如COCO或ImageNet数据集要小得多,这限制了算法的发展。
越来越多的研究者投入红外弱小目标检测,但上述问题共同构成了这一领域的研究难点。但如何在复杂的红外图像背景中,高效、准确、通用的检测出弱小目标,仍然是一个具有挑战性的难题[3] 。
赵鹏鹏,李庶中,李迅,等. 融合视觉显著性和局部熵的红外弱小目标检测[J].中国光学,2022,15(02):267-275.。
第二版
红外成像是将目标的红外辐射和背景信息转换成红外图像的过程,具有隐蔽性高、抗干扰性强、可远距离长时间工作等优点。在精确制导、防空预警等国防安全体系中,红外成像能够较早地检测到目标信息,为目标打击提供信息支撑,实现快速打击,具有极高的军事和现实意义。随着科技发展,新型无人机、航拍器等空中设备逐渐增多,法律监管也在逐步完善,但仍存在无人机“黑飞”及间谍利用无人机监视军事设施等问题。空中安全监管以及重点区域的安全保护和隐私防卫需要更加重视。
当前国际局势较为动荡,在俄乌冲突、巴以冲突中,双方使用无人机探查敌情并进行战术打击。防空系统如美国的“爱国者导弹”系统和以色列的“铁穹”系统对导弹等设备有较高的防御能力,但对低慢小无人机的防御表现有待提高。因此,检测和跟踪无人机等小型目标的能力需要引起重视,这对增强我国的航空安全和军事实力具有重大意义。
随着计算机硬件的进步以及深度学习的快速发展,计算机视觉各领域的精确度有了极大提升,红外目标检测也取得了显著进步。红外弱小目标检测是指在红外图像中识别和检测亮度较低、对比度不高的小型目标的过程。根据国际光学工程学会(SPIE)的定义,红外弱小目标是指尺寸不超过9x9像素的目标。其“弱”主要体现在目标的局部信噪比很低,与周围背景的差异很小,难以分离出来。而“小”则指目标所占的像素比例非常小,一般不超过总像素数的0.12%。由于像素数量少,这类目标通常没有明显的纹理特征,呈现为点状。
此外,红外成像系统依靠温差成像,相较于可见光图像,红外图像存在成像不清晰、容易被背景噪声淹没等问题,这对目标检测提出了更大的挑战。红外弱小目标检测的难点具体可分为以下几个方面:
- 目标尺寸小:在远距离红外成像中,目标通常只占据图像中极少的像素数,甚至可能只有一个像素,导致目标的形状、纹理等结构特征信息丢失,增加了检测难度。
- 信噪比低:红外图像中的目标信号容易受到大气衰减和传感器噪声等因素的影响,使得目标与背景之间的对比度较低,降低了目标的可检测性。
- 复杂背景:远距离成像时背景复杂,加上目标本身的辐射强度弱,这些因素共同作用下,目标很容易被背景淹没。
- 实时性要求:特别是在军事应用中,需要快速响应,这进一步提高了对检测算法的要求。
- 数据集限制:目前公开的红外弱小目标数据集数量较少,且数据量相比其他领域如COCO或ImageNet数据集要小得多,限制了算法的发展。
越来越多的研究者投入红外弱小目标检测领域,但上述问题共同构成了这一领域的研究难点。如何在复杂的红外图像背景中,高效、准确、通用地检测出弱小目标,仍然是一个具有挑战性的难题。
论文
深度学习
Infrared Dim Small Target Detection Networks: A Review
2014年R-CNN的推出标志着深度学习在目标检测领域的首次应用[32]。从那时起,基于深度学习的目标检测方法已经能够解决大量的目标检测问题。近年来,特别是在王等人的研究之后。 [33] 和戴等人。 [34]发布了红外小目标数据集,越来越多的研究人员将深度学习算法融入到红外弱小目标检测领域。他们根据红外小目标检测的特点定制设计深度学习网络,以提高检测性能。目前,有几篇文章总结了传统的单帧红外弱小目标检测方法[35-39]。
Gan
A Novel Pattern for Infrared Small Target Detection With Generative Adversarial Network
https://ieeexplore.ieee.org/abstract/document/9165022
Since existing detectors are often sensitive to the complex background, a novel detection pattern based on generative adversarial network (GAN) is proposed to focus on the essential features of infrared small target in this article. Motivated by the fact that the infrared small targets have their unique distribution characteristics, we construct a GAN model to automatically learn the features of targets and directly predict the intensity of targets. The target is recognized and reconstructed by the generator, built upon U-Net, according the data distribution. A five-layer discriminator is constructed to enhance the data-fitting ability of generator. Besides, the L2 loss is added into adversarial loss to improve the localization. In general, the detection problem is formulated as an image-to-image translation problem implemented by GAN, namely the original image is translated to a detected image with only target remained. By this way, we can achieve reasonable results with no need of specific mapping function or hand-engineering features. Extensive experiments demonstrate the outstanding performance of proposed method on various backgrounds and targets. In particular, the proposed method significantly improve intersection over union (IoU) values of the detection results than state-of-the-art methods.
由于现有探测器通常对复杂背景敏感,因此本文提出了一种基于生成对抗网络(GAN)的新型检测模式,以关注红外小目标的基本特征。鉴于红外小目标具有独特的分布特征,我们构建了GAN模型来自动学习目标特征并直接预测目标的强度。目标由基于 U-Net 的生成器根据数据分布进行识别和重建。构建五层判别器来增强生成器的数据拟合能力。此外,将 L2 损失添加到对抗性损失中以改善定位。一般来说,检测问题被表述为由 GAN 实现的图像到图像转换问题,即将原始图像转换为仅保留目标的检测图像。通过这种方式,我们可以在不需要特定的映射函数或手工工程特征的情况下获得合理的结果。大量的实验证明了所提出的方法在各种背景和目标上的出色性能。特别是,与最先进的方法相比,所提出的方法显着提高了检测结果的交并集(IoU)值。
1)我们提出了一种完全不同的模式,通过将检测问题建模为图像到图像的转换问题来完成红外小目标检测。
2)我们设计了基于U-Net的GAN架构来实现特征自动提取和目标估计。
3)引入L2损失来提高目标定位的精度。生成结果在评估指标方面显示出明显优于传统基线方法,包括信号杂波比增益(SCRG)、接收器工作特性(ROC)曲线、ROC曲线下面积(AUC)和并集交集(欠条)。
将我呢提分为三个部分,目标、背景、噪声
Miss Detection vs. False Alarm: Adversarial Learning for Small Object Segmentation in Infrared Images
A key challenge of infrared small object segmentation (ISOS) is to balance miss detection (MD) and false alarm (FA). This usually needs “opposite” strategies to suppress the two terms, and has not been well resolved in the literature. In this paper, we propose a deep adversarial learning framework to improve this situation. Departing from the tradition of jointly reducing MD and FA via a single objective, we decompose this difficult task into two sub-tasks handled by two models trained adversarially, with each focusing on reducing either MD or FA. Such a new design brings forth at least three advantages. First, as each model focuses on a relatively simpler sub-task, the overall difficulty of ISOS is somehow decreased. Second, the adversarial training of the two models naturally produces a delicate balance of MD and FA, and low rates for both MD and FA could be achieved at Nash equilibrium. Third, this MD-FA detachment gives us more flexibility to develop specific models dedicated to each sub-task. To realize the above design, we propose a conditional Generative Adversarial Network comprising of two generators and one discriminator. Each generator strives for one sub-task, while the discriminator differentiates the three segmentation results from the two generators and the ground truth. Moreover, in order to better serve the sub-tasks, the two generators, based on context aggregation networks, utilzse different size of receptive fields, providing both local and global views of objects for segmentation. As verified on multiple infrared image data sets, our method consistently achieves better segmentation than many state-of-the-art ISOS methods.
红外小目标分割(ISOS)的一个关键挑战是平衡漏检(MD)和误报(FA)。这通常需要“相反”的策略来抑制这两个术语,并且在文献中尚未得到很好的解决。在本文中,我们提出了一种深度对抗性学习框架来改善这种情况。与通过单一目标联合减少 MD 和 FA 的传统不同,我们将这项艰巨的任务分解为两个子任务,由两个对抗训练的模型处理,每个子任务都专注于减少 MD 或 FA。这样的新设计至少带来三个优点。首先,由于每个模型都专注于相对简单的子任务,ISOS 的整体难度有所降低。其次,两个模型的对抗性训练自然会产生 MD 和 FA 的微妙平衡,并且在纳什均衡下可以实现 MD 和 FA 的低比率。第三,这种 MD-FA 分离使我们能够更加灵活地开发专用于每个子任务的特定模型。为了实现上述设计,我们提出了一种由两个生成器和一个判别器组成的条件生成对抗网络。每个生成器都致力于一个子任务,而鉴别器则区分两个生成器和地面实况的三个分割结果。此外,为了更好地服务子任务,两个基于上下文聚合网络的生成器利用不同大小的感受野,提供对象的局部和全局视图以进行分割。经过多个红外图像数据集的验证,我们的方法始终比许多最先进的 ISOS 方法实现更好的分割。
Infrared small object segmentation (ISOS) ISOS 任务被分解为两个子任务,即最小化 MD 和最小化 FA。构建两个深度神经网络分别专注于这两个任务。两个网络扮演生成器的角色,各自输出一个分割结果。为了使两个分割结果与地面真实分割结果一致,构建了一个判别器网络来对上述三个结果进行分类。这样,两台发电机就以一种有趣的“竞争与合作”的方式工作。通过竞争,他们努力将像素分别最大限度地分割为物体或背景。通过合作,它们相互协商(即平衡),以向地面实况分割方向收敛,从而欺骗鉴别器。给定测试图像,任一生成器的输出(或其平均值)将是分割结果。整个框架可以通过扩展条件生成对抗网络来轻松实现
接下来。首先,我们通过采用对抗性学习范式,提出了一种用于红外小物体分割的新颖框架。去掉了显式平衡MD和FA的负担,能够以隐式自然的方式达到微妙的平衡;其次,利用 MD 和 FA 最小化的可分离性,将 ISOS 任务分解为两个单独的且更简单的子任务。与现有的使用单个网络进行分割的方法相比,我们的方法可以降低模型和网络设计的整体难度。第三,上述分离带来的直接优势是开发最适合子任务的模型的额外灵活性,这在我们的工作中得到了证明,如下所示。我们发现在ISOS中,对象的分割更倾向于局部视觉信息,而误报的抑制则受益于全局视觉信息。为了满足这个要求,我们通过上下文聚合网络在两个生成器中使用不同大小的感受野[15]。如果不分离两个子任务,实现这种特殊设置即使不是不可能,也可能会很尴尬。最后,我们在多个红外图像数据集上将我们的方法与相关最先进的小目标分割方法进行比较。结果很好地证明了所提出方法的优越性及其有趣的特性。
U型网络
SCTransNet: Spatial-Channel Cross Transformer Network for Infrared Small Target Detection
1.图像去噪
原理:
自编码器通过两个主要的神经网络组件实现图像去噪:编码器和解码器。编码器负责将输入图像映射到一个隐藏的表示空间(也称为潜在空间),而解码器则负责从这个潜在表示重构图像。
编码器:接收含噪声的图像,通过逐层压缩数据,学习到一个潜在的、更紧凑的表示形式。这一过程中,网络被迫学习忽略噪声,只保留最重要的图像特征。
解码器:接收潜在空间中的紧凑表示,通过逐层扩展数据,重构去噪后的图像。理想情况下,重构的图像应该接近原始图像,而不包含噪声。
实现:
在训练过程中,自编码器的目标是最小化重构图像与原始无噪声图像之间的差异,通常使用均方误差(MSE)作为损失函数。通过这种方式,模型学习到如何有效地去除输入图像中的噪声。
2.特征提取和降维
原理:
自编码器在特征提取和降维中的应用基于其能力将数据编码到一个低维潜在空间。这个过程捕获了输入数据的关键信息,同时去除了冗余。
编码器:将高维输入数据(如图像)映射到一个低维表示。这个低维表示是输入数据的一个压缩形式,包含了最重要的特征。
解码器:尝试从这个低维表示重构原始输入。如果重构质量高,这表明低维表示成功捕获了输入数据的关键信息。
实现:
通过训练自编码器最小化输入与重构输出之间的差异,模型学习提取数据的有效特征。这些特征可以用于各种下游任务,如分类或聚类,提高了处理效率和性能。